Member-only story
Multi-processing in Python; Process vs Pool
You know my code runs more than one computation on same input. All these different computations provide me different kind of results and do not share any dependency on each other. But for the time being all of them run synchronously, i.e. one after the other. How could i reduce the time of my overall computation?

Lets Employee Parallel Processing
The solution to such a problem is Multi-processing. But hey some of you have heard of multi threading as well, cant I employ that here. Well, Threads uniquely run in the same unique memory heap where as Processes run in separate memory heaps. This makes sharing information harder with processes and object instances. One problem arises because threads use the same memory heap, multiple threads can write to the same location in the memory heap which is why the global interpreter lock(GIL) in CPython was created as a mutex to prevent it from happening.
What is global interpreter lock(GIL)
CPython is the reference(standard) implementation of the Python Programming Language. Written in C and Python, CPython is the default and most widely used implementation of the language. It can be defined as both an interpreter and a compiler as it compiles Python code into byte-code before interpreting it. A particular feature of CPython is that it makes use of a global interpreter lock (GIL) on each CPython interpreter process, which means that within a single process only one thread may be processing Python byte-code at any one time.
This does not mean that there is no point in multi threading; the most common multi-threading scenario is where threads are mostly waiting on external processes to complete.
Concurrency of code
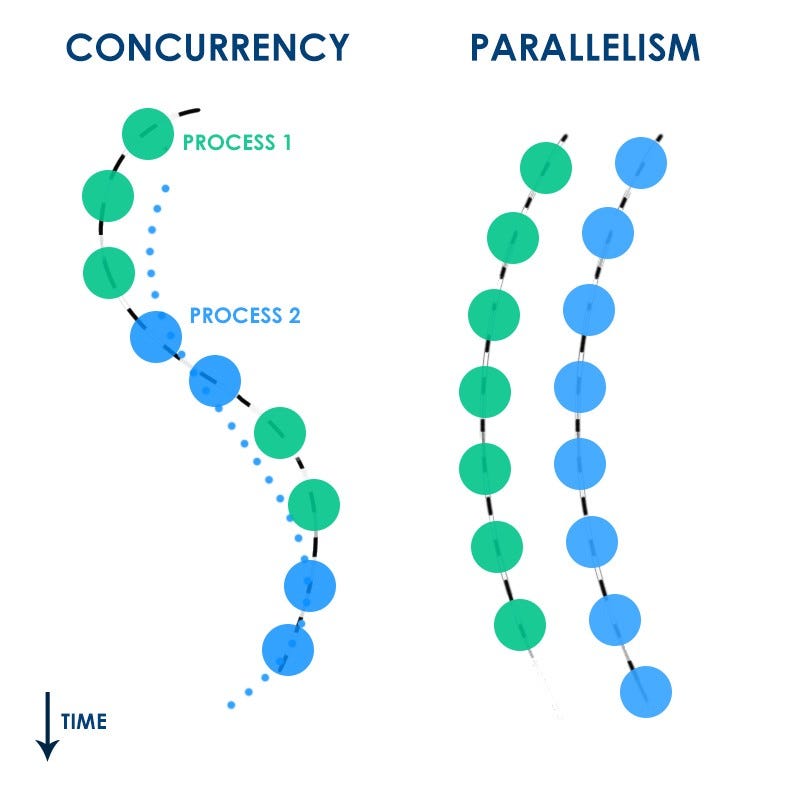
Concurrency of Python code can only be achieved with separate CPython interpreter processes managed by a multitasking operating system. This complicates communication between concurrent Python processes, though the multiprocessing module mitigates this somewhat; it means that applications that really can benefit from concurrent Python-code…
